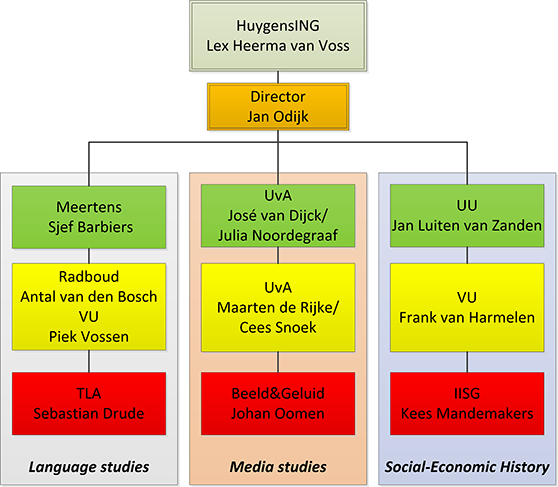
Presentations Mini-seminar: Disambiguating entities and their roles in texts based on background knowledge on December 12, 2014:
– Introduction (pdf) by Prof. dr. Piek Vossen
– Towards a Dutch FrameNet-style Semantic Role Labeler (pdf) Presentation by Chantal van Son
– Named Entity Disambiguation with two-stage coherence optimization (pdf) Presentation by Filip Ilievski
Invitation below:
Mini-seminar: Disambiguating entities and their roles in texts based on background knowledge
Dear all,
We cordially invite you to our mini-seminar “Disambiguating entities and their roles in texts based on background knowledge ” in which we will present our Master’s thesis topics and the current/future work. It will take place on Friday, December 12 from 10:00 to 12:00 in room C-121 (W&N Building).
An array of text processing tools is currently used to extract events, recognize and link entities, and discover relations between the two. We, Filip Ilievski and Chantal van Son, tackle these type of Natural Language Processing tasks by using background knowledge from lexical resources and the Semantic Web. The disambiguation of entities and their context is in the core of both approaches: Filip’s thesis aims to disambiguate them by determining their identity while Chantal’s thesis aims at disambiguating the roles they play in context. You can find the descriptions of both projects below.
Prof. Piek Vossen will kick-off the mini-seminar by depicting the background of the problem and presenting the existing approaches. Prof. Frank van Harmelen will conclude the event with a discussion on the integration of background knowledge in language processing.
Program:
10:00 – 10:15 Introduction by Piek Vossen
10:20 – 10:50 Towards a Dutch FrameNet-style Semantic Role Labeler (Chantal van Son)
10:55 – 11:25 Named Entity Disambiguation with two-stage coherence optimization (Filip Ilievski)
11:30 – 12:00 Closing remarks and discussion lead by Frank van Harmelen
Towards a Dutch FrameNet-style Semantic Role Labeler (Chantal van Son)
Semantic role labeling (SRL) is one of the key tasks in Natural Language Processing for deep text understanding. Because of its rich and fine-grained categorization of different conceptual scenarios and their specific semantic roles, FrameNet is a popular resource to serve as a basis for SRL systems in English. For Dutch however there is currently no FrameNet-like resource available that can be used to train a SRL system, and creating such a resource usually takes a great deal of expensive manual effort. This study investigates how existing tools and resources, such as the SoNaR Semantic Role Labeler (SSRL) and the Predicate Matrix, can be exploited for FrameNet based SRL in Dutch. In this talk I will present this method while discussing some of its difficulties and possible solutions to solve them.
Named Entity Disambiguation with two-stage coherence optimization (Filip Ilievski)
Contemporary Natural Language Processing modules solve Entity Linking, Event Detection, and Semantic Role Labeling as separate problems. From the semantic point of view, each of these processes adds another brush-stroke onto the canvas of meaning: entities and events are components that occur in relations which correspond to roles. The approach presented here extends such NLP processes with a semantic process of coherence optimization. I use both binary logic and probabilistic models built through manual and automatic techniques. The binary filtering phase relies on restrictions from VerbNet and a domain-specific ontology. The optimization phase aims to maximize the coherence between the remaining candidates in a probabilistic manner based on available background knowledge about the entities.
Kind regards,
Filip Ilievski & Chantal van Son